Everyone love life “hacks.”
Even I too love finding ways to make my life easier and better.
And today, I am revealing one of my secret technique which can boost your website ranking and this one is my favorite. It is a genuine SEO hack that you can immediately implement into your WordPress website to get your website crawled faster by GoogleBot.
It is another way to improve your SEO by taking the benefit of a natural part of the website that experts rarely disclose with you and trust me, it’s not hard to implement either.
It is robots.txt file also known as robots exclusion protocol.
This little file is a part of every website that exists on the internet, but most of the people even don’t know about it.
Basically, the robots.txt file is designed to work with major search engines but, it’s a great source of SEO juice which is waiting to get unlocked for your WordPress website.
I have many clients who talk about SEO for their organic rankings but when I explain them to edit this tiny robots.txt file, they get shocked and don’t believe my words.
However, there are several methods to enhance your website SEO and they are not difficult too, and this is one of the greatest methods among them.
Trust me!
You don’t need to have any huge technical experience or programming knowledge to leverage the power of robots.txt file but if you can find your website’s source code, you can do it easily.
Once you are ready, continue reading and I will show you how to optimize your Robots.txt file for WordPress website to rank faster and loved by search engines.
Why Robots.txt file is too important?
Let’s discuss why the robots.txt file matters in terms of organic rankings.
The robots.txt file which is also known as robots exclusion protocol or standard is a simple text file that tells the search engines(web robots) which pages need to be crawled by them.
Also, it tells the search engines which pages should not be crawled by them.
How do the search engines get instructions?
When you submit the site to Google Webmasters or any other Webmasters, then web robots(search engines) visit to your site and before fetching/crawling any of the pages, firstly they visit the robots.txt file and read the instructions over there.
In case, if the file is missing then they start crawling all the pages of your website which takes a while for them to complete the crawling process.
Do you really know how many pages your website have?
Most of the users think they just have limited pages into their website’s pages tab(in case of WordPress website) like six to ten but you are missing category pages as “/category/” or tags as “/tags/”.
Likewise, there are numerous pages into your WordPress or other framework based website that you literally can’t count easily.
But, search engines crawl them one by one by and this takes a lot of time.
Don’t allow search engines to crawl every page of your website
Really?
Let me demonstrate to you why I am saying this and why it is necessary to limit the search engines not to crawl every single page of your website.
There are few pages into your website which you would really don’t want to get ranked.
For example: If I have a WordPress website then why would I like to rank my WordPress login page https://websoftglobal.com/wp-admin/ ???
In the same way, if you have a landing page where people can subscribe and you display a Thank You page to them after subscription, is there any need to rank that specific Thank you page on Google search engine?
Why people will be interested to just view a Thank You page with a text “Thanks for subscribing us. We will send you XXXXXX stuff”?
It means, we have to restrict such pages to get crawled and ranked which do not have any motive to get visible to users.
And here, in this case, Robots.txt helps you to tell search engines not to crawl such pages.
Let’s have a look at robots.txt file structure.
User-agent: *
Disallow: /
This is the basic structure of a robots.txt file on WordPress website or any other site.
The asterisk (“*”) after User-agent specify that the robots.txt file applies to all the search engines that visit the website.
In the second line, a slash (“/”) after “Disallow” tells the web robot not to visit any of the pages on this website.
Sounds Weird?
You must be thinking why I or someone want to stop search engines to visit my website, though, for higher and faster rankings, it is important that the search engines should visit our website.
This is where the SEO hack secret reveals.
As I explained above, there is no need for those pages to get crawled by the search engines which have no chances of conversion or do not help your other pages rankings.
After all, if all of the pages of your website get start crawling by GoogleBot or other web robots then it will take a lot of time which results in negative rankings.
Because GoogleBot has a crawl budget to crawl links of your website.
Google Crawl Rate Limit
- It has been designed to help Google not to crawl each and every page of your website and not too fast where it hurts your web server.
- Crawl demand depends on the amount of web pages needs to be crawled by Google. This is completely based on the popularity of your webpages and how old is your content resides in the Google Index.
Crawl Budget:
It is defined by Google as the number of links the GoogleBot can crawl and wants to do.
Where to find Robots.txt for WordPress website?
Well, it is not too tricky.
Simply, just after your website’s full domain, type robots.txt followed by slash “/”.

1. If Robots.txt file in your website exist then it will be displayed similar to the above snapshot.
2. If you find an empty page something similar to the below one.
3. Or if you get a 404 page not found something like this:
 Then you need to create a robots.txt file, and it is really important, trust me.
Then you need to create a robots.txt file, and it is really important, trust me.
May be you find a valid robots.txt file but it is probably set to default settings as it was created when you someone make a website.
I usually like the method of [domain-name]/robots.txt to look out other websites robots.txt files. Once you learn each and everything about robots.txt, this will become your regular exercise, valuable for organic rankings.
Alright, let’s jump into the next section to create a robots.txt file, in case if it is missing in your website.
If robots.txt file is missing in your website then you need to create one from scratch.
Use a plain text editor for creating this file like Notepad in Windows or TextEdit in MAC.
Why to use a plain text editor?
If you would be using Microsoft Word on Windows PC or Pages on MAC then few addtional lines of code can be added and ruin up the whole file.
There is a great option to create such file online by visiting to Editpad.org.
Jump back to robots.txt
If this file exist in your website then you need to locate it into your website’s root directory by opening file manager in your web hosting CPanel.
If you are not used to play with the source code then it could be a little difficult for you to find and edit this file.
Usually, use any FTP program like filezilla to access your site’s root folder or directly login into your web hosting’s CPanel.
I should look something like this:
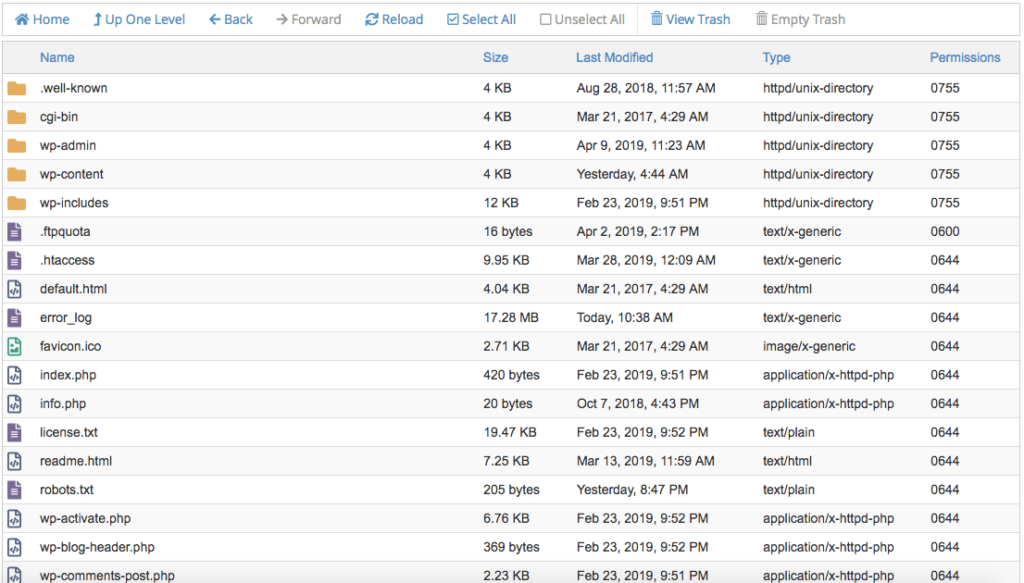
In the above snapshot as you can see there is a robots.txt file exist for my website.
In order to edit the file, simply right click on it and then push Edit/Download button.
Robots.txt for WordPress website doesn’t exist
If your website is using WordPress as the platform then robots.txt file can’t be found in your root directory.
Why?
The reason is that WordPress create a virtual robots.txt file and in this case you will be needing to create a new robots.txt file using a plain text editor.
Edit Robots.txt file
Here, I am gonna guide you how to optimize robots.txt for SEO so that you website can start getting more and more traffic with fast crawling of pages.
1. Setting up User-agent term: User-agent specifies that all web robots are welcome to your website or blog. So, it should be written as:
User-agent: *
Using an asterisk (“*”) after the User-agent makes it clear to all the web robots to crawl your website.
2. In the next line, type “Disallow:” and after that, exclude those URL which are not needed to get ranked in the following format:
Disallow: /wp-admin/ Disallow: /tag/ Disallow: /author/ Disallow: /category/ Disallow: /page/
Where, /wp-admin/, /tag/, etc. are your website’s/blog’s links which are not needed to get ranked by the Google or any major search engines as what is the need of ranking your website’s admin URL on Google 1st page?
“Disallow: /wp-admin/” means now when the web crawler visit to your robots.txt file, it won’t crawl the page https://[your-domain]/wp-admin/
3. Link your XML Sitemap: It is super easy to link your website’s XML sitemap with this robots.txt file in the following manner.
Sitemap: https://websoftglobal.com/sitemap_index.xml
Testing Robots.txt with Google Webmasters
Once you are done with the steps explained above in order to edit or create a robots.txt file, it’s time to check whether this file is valid or not.
Google Webmasters Tool help you to perform this check.
1. Go to Google Webmasters Tool and login into your account.
2. Once you are in, navigate to the crawl option and then robots.txt tester.
When you click on robots.txt texter, your file can be displayed immediately with the content that you placed into it.
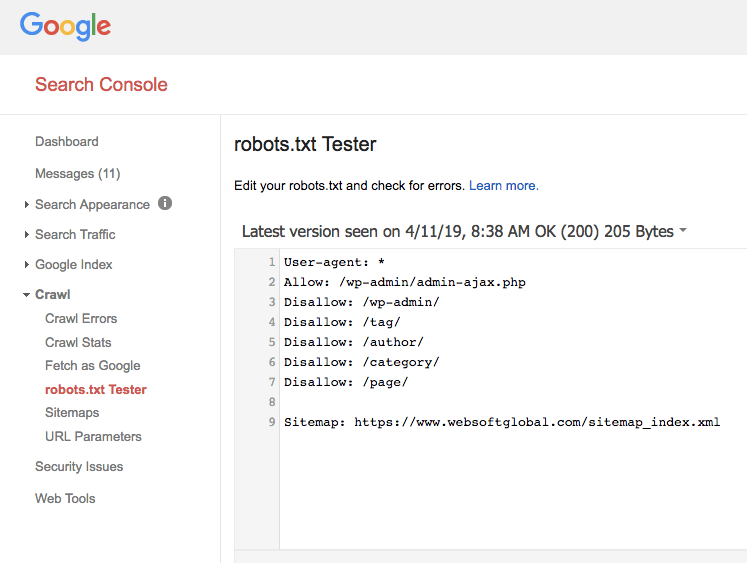
3. In case, if you see something wrong then make a robots.txt file check using the tester on the same page.

Conclusion
I love to share my experiences in SEO hacks with you and even digging out more to help you for improving your organic rankings.
By optimizing your Robots.txt, you are not just enhancing your SEO but also helping your visitors to get information on the right page only.
All search engines visit your robots.txt file in order to get instructions of what pages need to be skipped from crawling. This reduce crawl budgets wisely and hence, there are more possibilities for your blog and website to get visible in the SERPs.
You might be interested in these articles too:







